Představte si na okamžik, že hledáte zdravotní doporučení.
Místo Googlu se obrátíte na nejnovější chatbot s umělou inteligencí (AI), který vám podá jednoduchou radu: přestaňte jíst „chlorid sodný“ (kuchyňskou sůl) a nahraďte ho „bromidem sodným“ – látkou, která může způsobit toxicitu a ovlivnit dýchací, nervový i hormonální systém.
Ačkoli to může znít přitažené za vlasy, tento incident se skutečně odehrál ve Spojených státech, kde 60letý muž onemocněl poté, co tři měsíce užíval bromid sodný.
Muž lékařům řekl, že se na ChatGPT dotazoval, čím lze stolní sůl nahradit, a že mu tato látka byla doporučena.
Aby lékaři ověřili zjištění, položili ChatGPT stejnou otázku, a program AI opět navrhl bromid.
Znepokojivé bylo, že nedoplnil žádná zdravotní varování, přičemž výzkumníci navíc zjistili, že není možné dohledat zdroje, z nichž by závěr vycházel.
V jiném, zdánlivě nesouvisejícím případě z října 2025 musela konzultační společnost Deloitte, jedna z „Velké čtyřky“, částečně vrátit australské federální vládě náklady na zpracování zprávy (97 000 australských dolarů, tedy přibližně 1,6 milionu korun). Ukázalo se, že použila generativní AI, která ve svých doporučeních citovala neexistující zdroje.
Co jsou halucinace umělé inteligence?
Tyto jevy jsou nyní označovány jako „halucinace AI“.
Popisují situaci, kdy program umělé inteligence zaplňuje mezery ve znalostech tím, že si domýšlí vlastní závěry nebo nesprávně interpretuje data.
Proč k tomu dochází?
Umělá inteligence – navzdory svému názvu – ve skutečnosti nemá vlastní „inteligenci“.
Místo toho se učí jazykovým vzorcům (například struktuře vět, kontextu, tónu a dalším) a „trénuje se“, aniž by skutečně chápala význam slov.
Za těchto podmínek vzniká velká pravděpodobnost, že programy umělé inteligence budou „halucinovat“ a generovat vlastní závěry jako reakci na miliony dotazů, které jim lidé denně zadávají.
Například níže uvedený obrázek byl vytvořen v Microsoft Copilot na dotaz: „Můžeš nakreslit mapu světa a vyznačit všechny země, které začínají na písmeno S?“
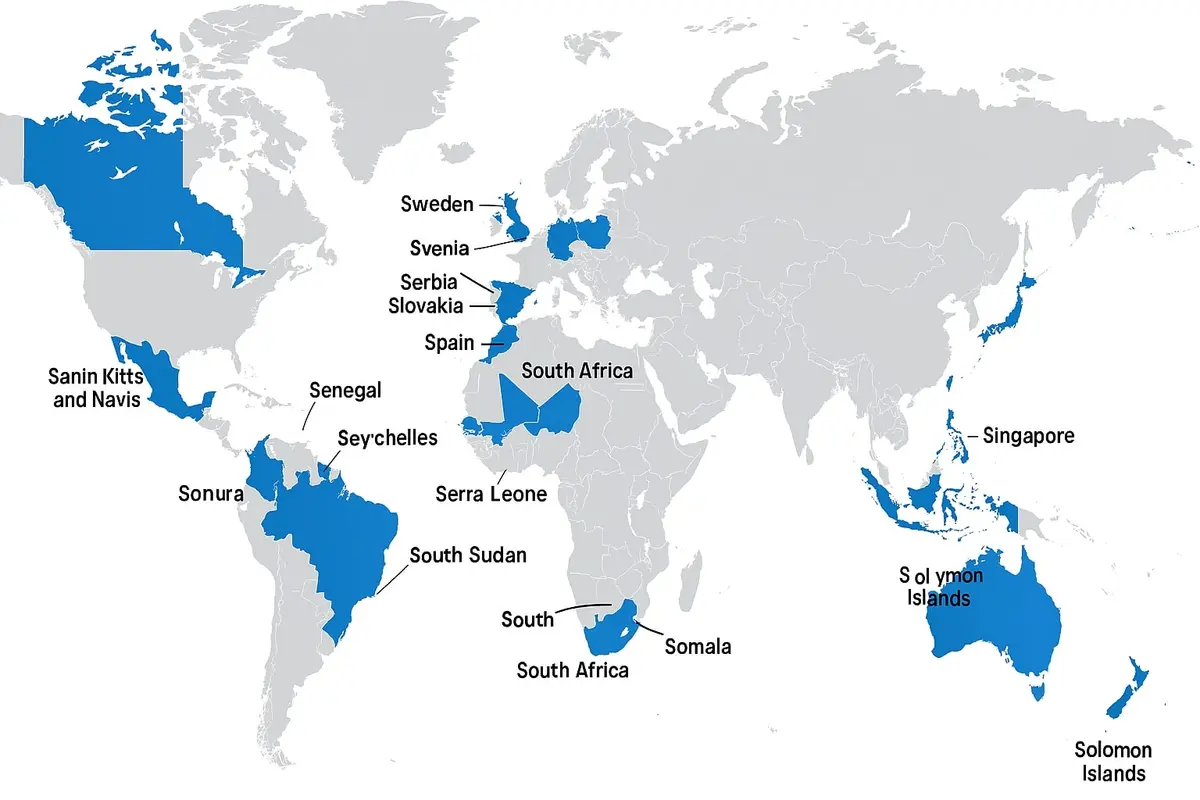
Záleží na tom?
Paul Darwen, akademický vedoucí a výzkumník v oblasti umělé inteligence na James Cook University, uvedl, že existují dvě hlavní obavy týkající se halucinací AI.
„Prvním a nejzřejmějším důvodem je, že lidé se ptají chatbotu na téma, o kterém toho moc nevědí (jinak by se neptali), takže nedokážou posoudit, jak přesná odpověď je. I když je odpověď naprosto nesmyslná, mají tendenci jí slepě věřit,“ řekl pro Epoch Times.
Darwen sdílí, že druhou, méně zjevnou obavou je přispívání k poklesu vzdělávacích standardů mezi mladší populací.
Vysvětluje, že jednou z největších skupin uživatelů generativní AI jsou školáci, přičemž poukázal na americké statistiky, které ukazují, že používání ChatGPT klesá během prázdninového období přibližně o 75 procent.
„To naznačuje, že mladí lidé se neučí číst a psát, ani si nedokážou vytvořit mentální model světa, protože svou výuku mohou jednoduše outsourcovat na ChatGPT,“ uvedl Darwen.
„Pokud budeme shovívaví a připustíme, že někteří studenti používají chatovací programy jako interaktivního učitele, pak chatbot někdy halucinuje a jejich mladé mysli zaplňuje nesmysly.
„To vytváří celou generaci mladých lidí s chatrným pochopením toho, co je v širším světě skutečné. Není to hned patrné, protože stále získávají vyhovující známky, ale později v životě to povede ke špatným rozhodnutím.“
Jak zabránit tomu, aby společnost upadla do pasti halucinací
Jak se generativní umělá inteligence stává pokročilejší a „chytřejší“, má tendenci halucinovat více. V kombinaci s rostoucí dostupností AI začíná problém ovlivňovat celou společnost.
Darwen proto věří, že zveřejňování příkladů halucinací může pomoci společnost vůči nim „proočkovat“.
„Lidé mají tendenci předpokládat, že dostávají poctivé odpovědi, takže když vidí odpovědi, jejichž validitu mohou posoudit, uvědomí si, jak běžné halucinace AI jsou,“ podotýká Darwen.
„Dalším přístupem je požádat někoho, aby chatbotu položil otázku, na kterou zná odpověď pouze on (člověk), a zjistit, zda chatbot odpoví ‚nevím‘ nebo zda si místo toho vymyslí halucinaci.“
Akademik uvádí, že chatboty mají tendenci poskytovat odpověď, místo aby přiznaly, že odpověď neznají.
Ideálním řešením by bylo řešit problém u samotného zdroje – trénovat modely AI na rozmanitých a kvalitně definovaných datech, omezit typ odpovědí, které mohou generovat, a další podobné kroky.
To však může být za současného stavu technologie obtížné.
–ete–